網頁由HTML+CSS+JavaScript組成
爬蟲是指透過網址(URL)自動抓取網頁內容的程式
URL分成三部分:協議(http/https,Hypertext Tranfer Protocal) + 存有該資源的主機位址(140.112.8.116 / www.ntu.edu.tw ) + 主機上的具體目錄或文件名稱(about/about.html,這部分視情況加上)
140(education) 112(台大)
DNS (Domain Name Service)
查自己的電腦現在所在ip位置:
Windows - 使用 cmd 打 ipconfig
Mac/Linux - 使用 terminal 打 ifconfig
對查詢IP位置是源自哪個地址有興趣的人可以到WHOIS玩玩看
網路規範制定組織:
post/get (資訊隱密性低,比較好寫)
#看網站原始碼
Step 1. 在 Google Chrome 點右鍵選 Inspect

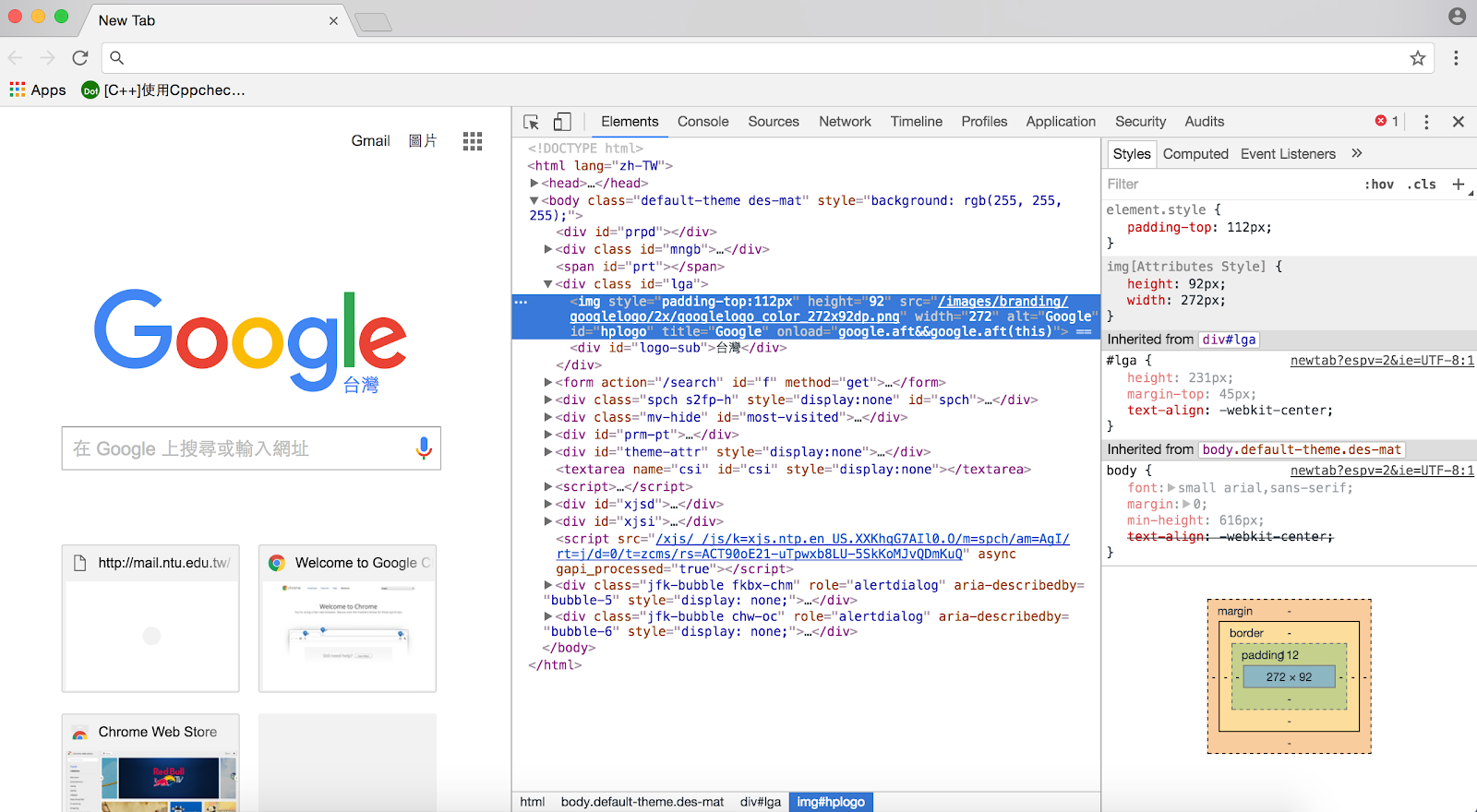
看到上面這個圖就是Html 跟 CSS了
Step 2. 試著改背景顏色,注意你不會因為改了內容就改變這個網站,只有自己可以看到而已

測試 Response
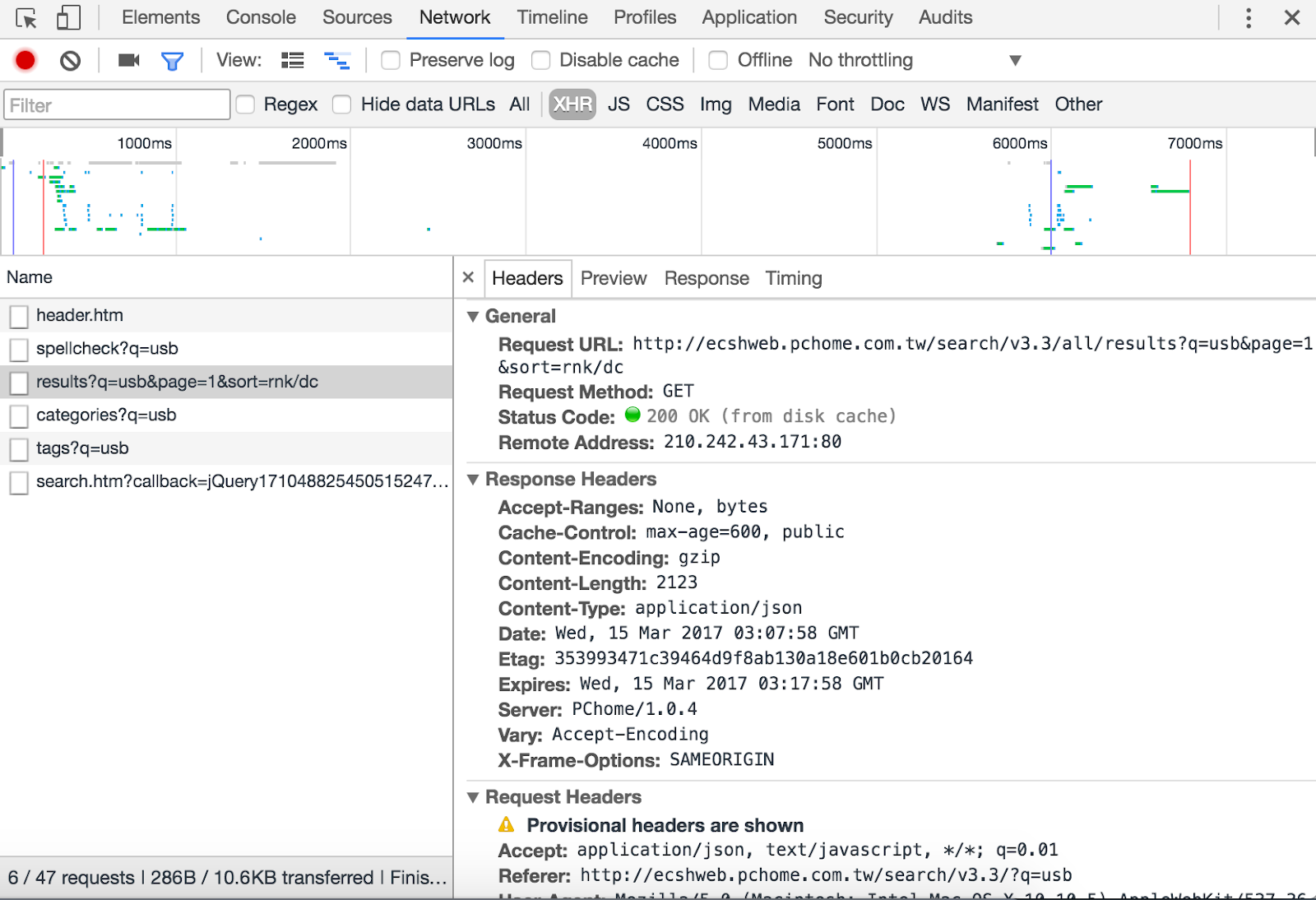
Step 1. 點選 Network
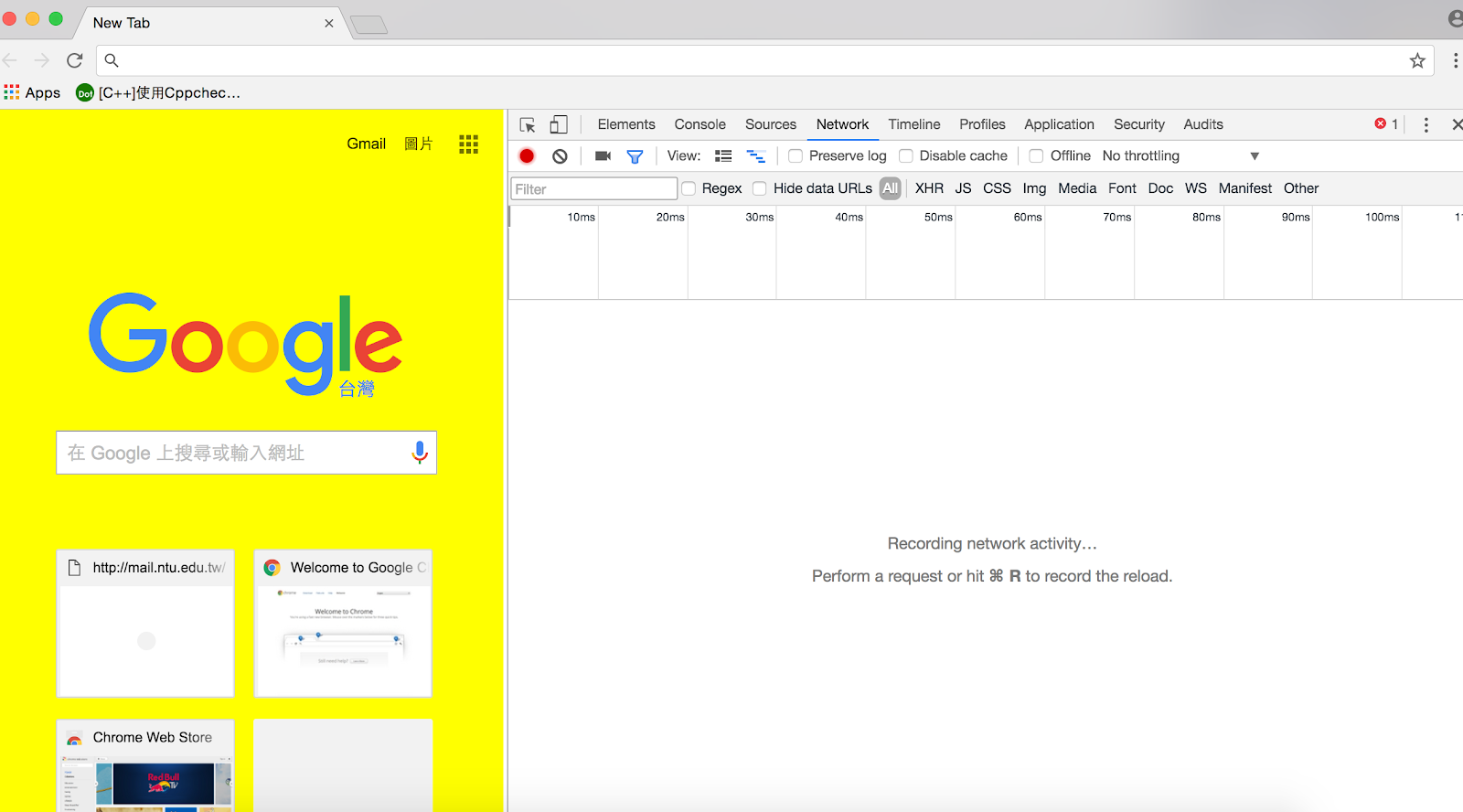
Step 2. 點選左上角 Stop Recording

Step 3. 重新整理頁面
Step 4. 可以看到回傳的內容
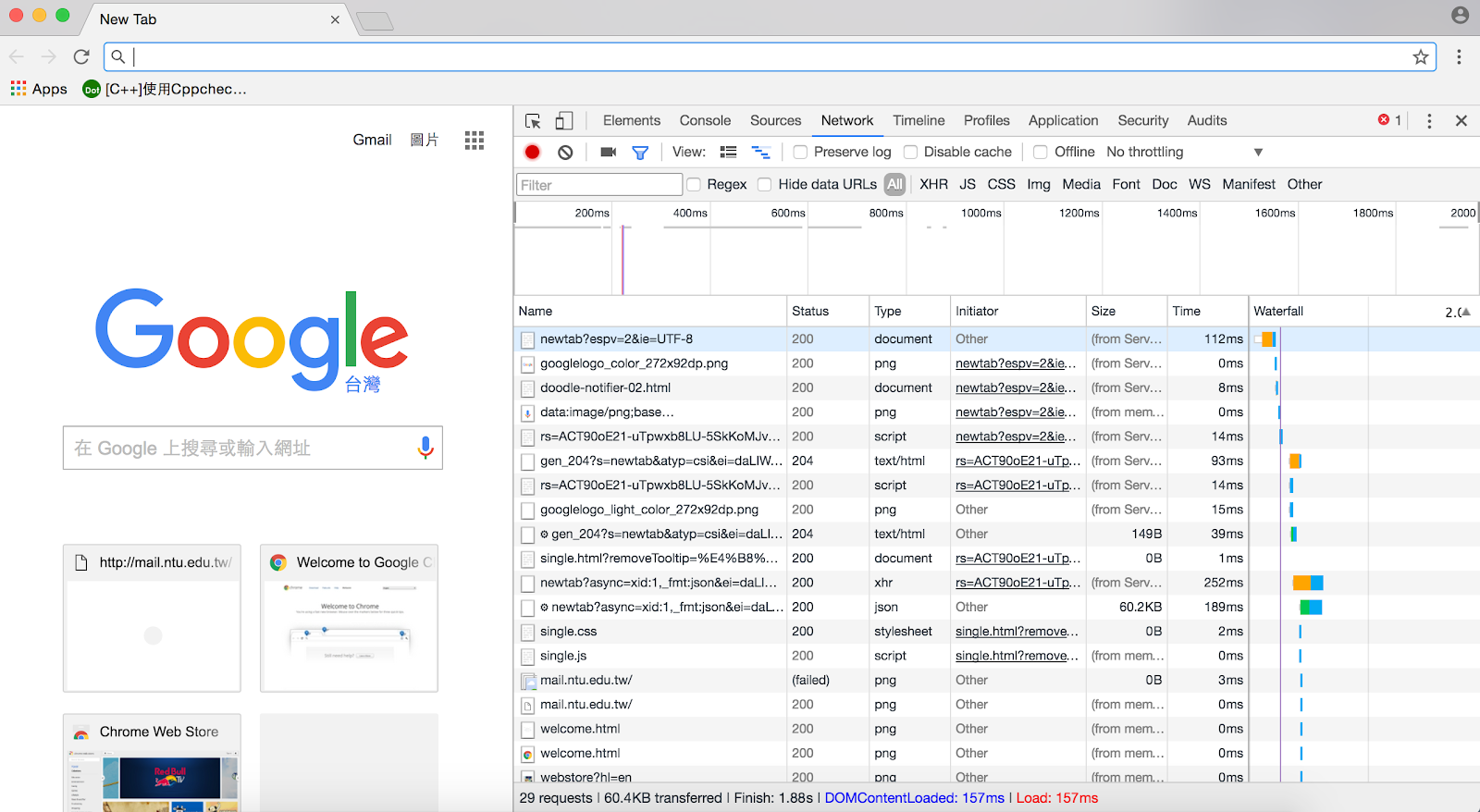
XHR - 寬鬆標準的html (XMLHTTP)
點選下去可以直接看到爬蟲需要資訊,省時間

點選你想要使用的資訊欄,可以看到右邊視窗提供你 Request URL 使用
Option :下載 Postman- 測試 API ,模擬 HTTP requests (貼網址後,按 Post 再按 send)
須先安裝 httr / XML / xml2 ----
install.packages("httr")
install.packages("XML")
install.packages("xml2")
Code 1 : 在GET指令裡貼上你在 XHR 找到的 Request URL
library(httr)
rawdata1 <- data1$content
Code 2:連續抓好幾個網頁資訊,以 ptt movie 板為例
library(httr)
library(XML)
subURL = 'https://www.ptt.cc/bbs/movie/index'
startid = 1000
endid = 1010
for(pid in seq(startid,endid))
{
url = paste0(subURL,pid,'.html')
data = GET(url)
rawData = htmlParse(content(data))
print(rawData)
}
網路概念延伸課程:
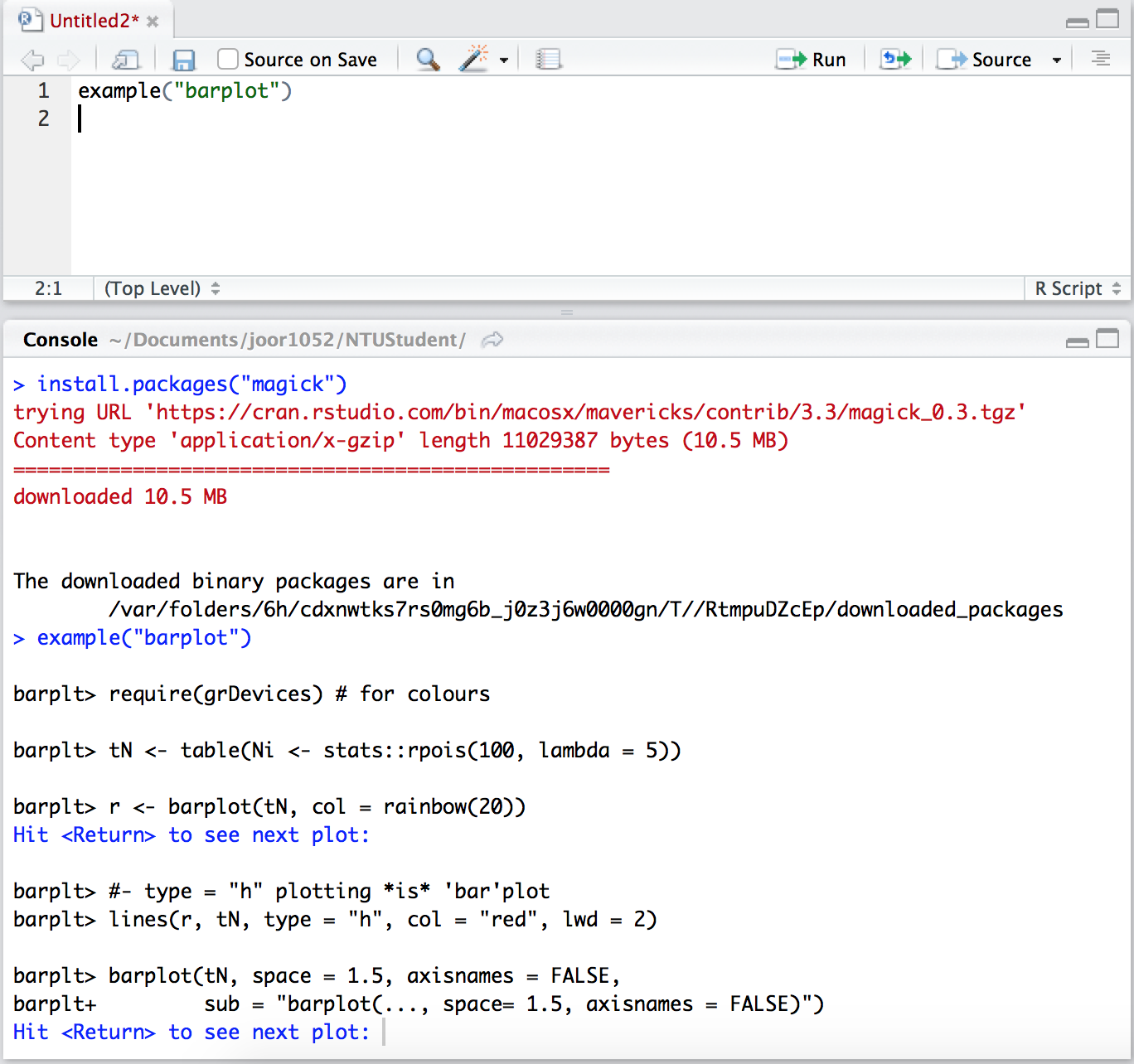
在 Rstudio 裡開新檔案,打 example("barplot")
按 Enter 就可以看到下一個範例
爬蟲教學(下)
# 網頁架構及語法:
**<標籤> 內容 </標籤>
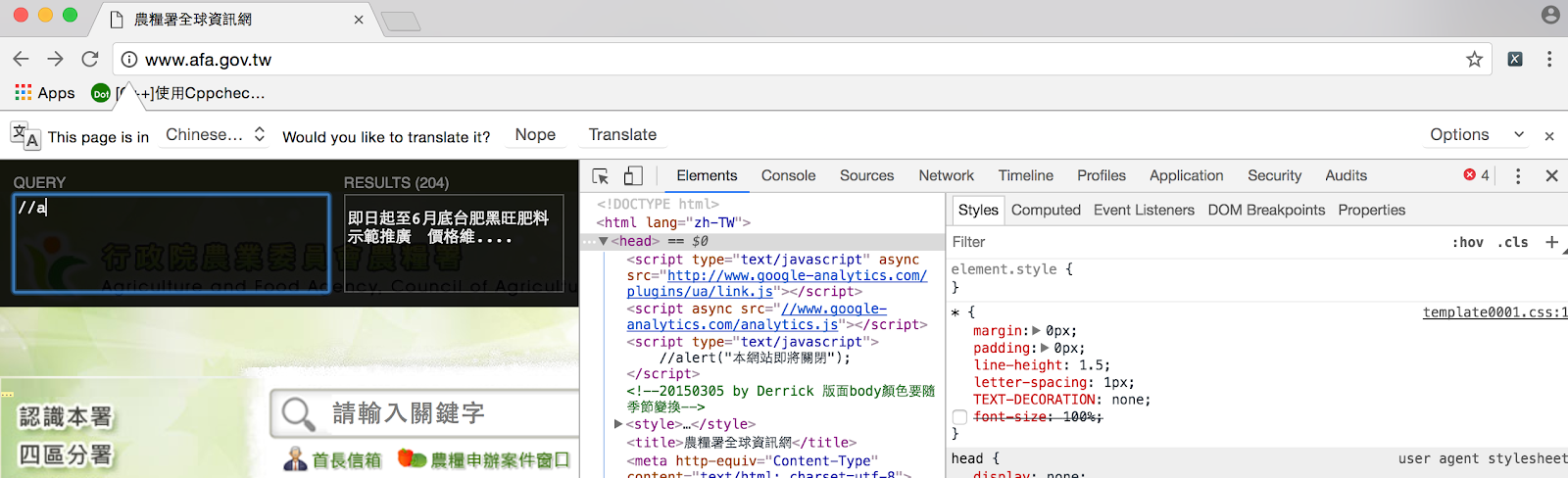
#[下載 X path helper](https://chrome.google.com/webstore/search/X path helper?hl=zh-TW),點選第一個的 加到 Chrome,右上角可以看到黑色方框 X 就成功了**

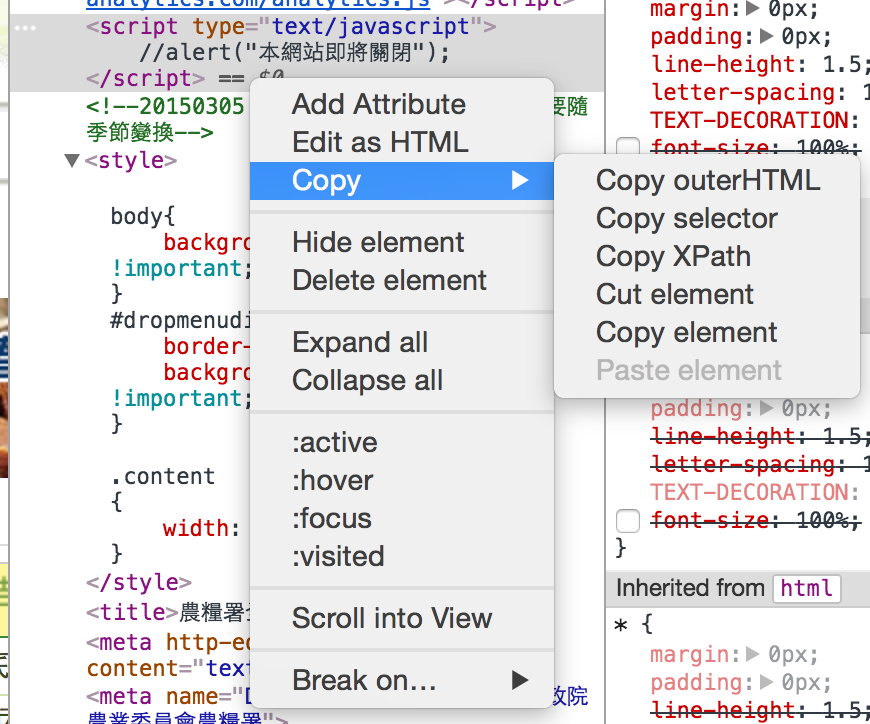
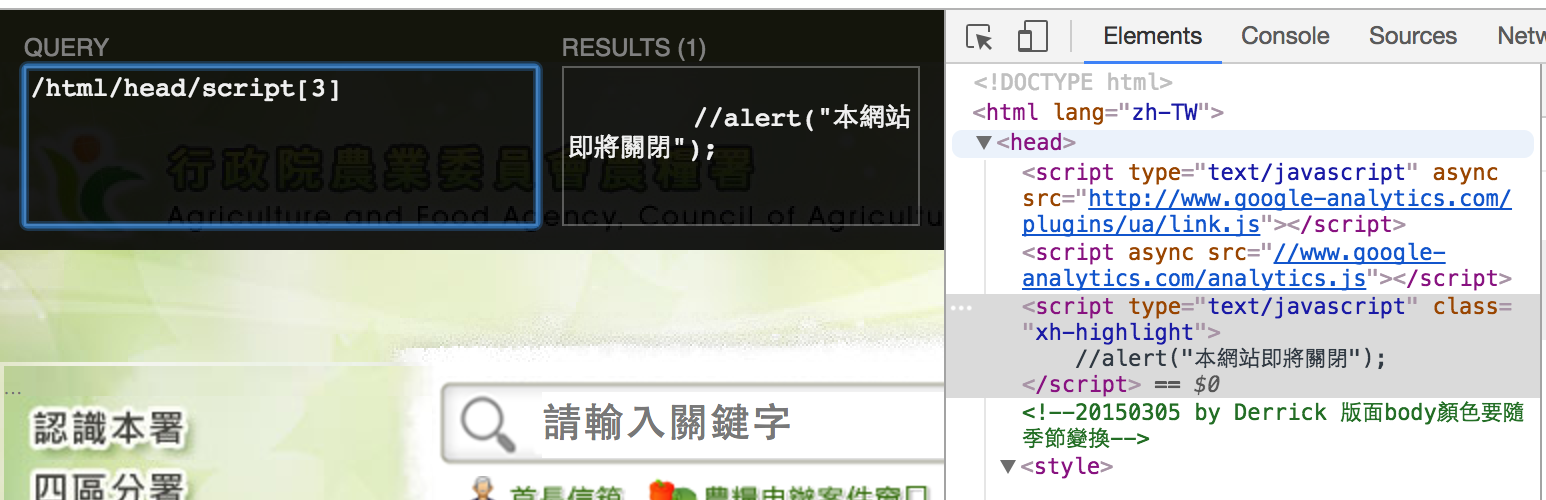
到農糧署網站測試,使用 Chrome 點左鍵檢查,點開 X path helper 打 //a,就可以看到被標籤 a 夾住的內容
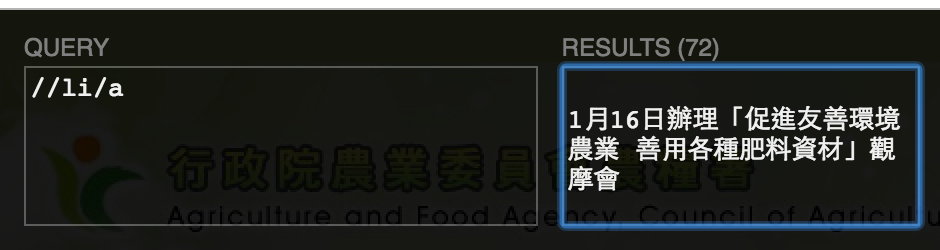
打 //li/a 就可以看到在 li 下的 a 裡面的內容
- 也可以對你想要使用的資料點右鍵選擇 Copy > Copy Xpath , 複製好後,在X Path Helper 點選貼上,就可以搜尋到指定內容
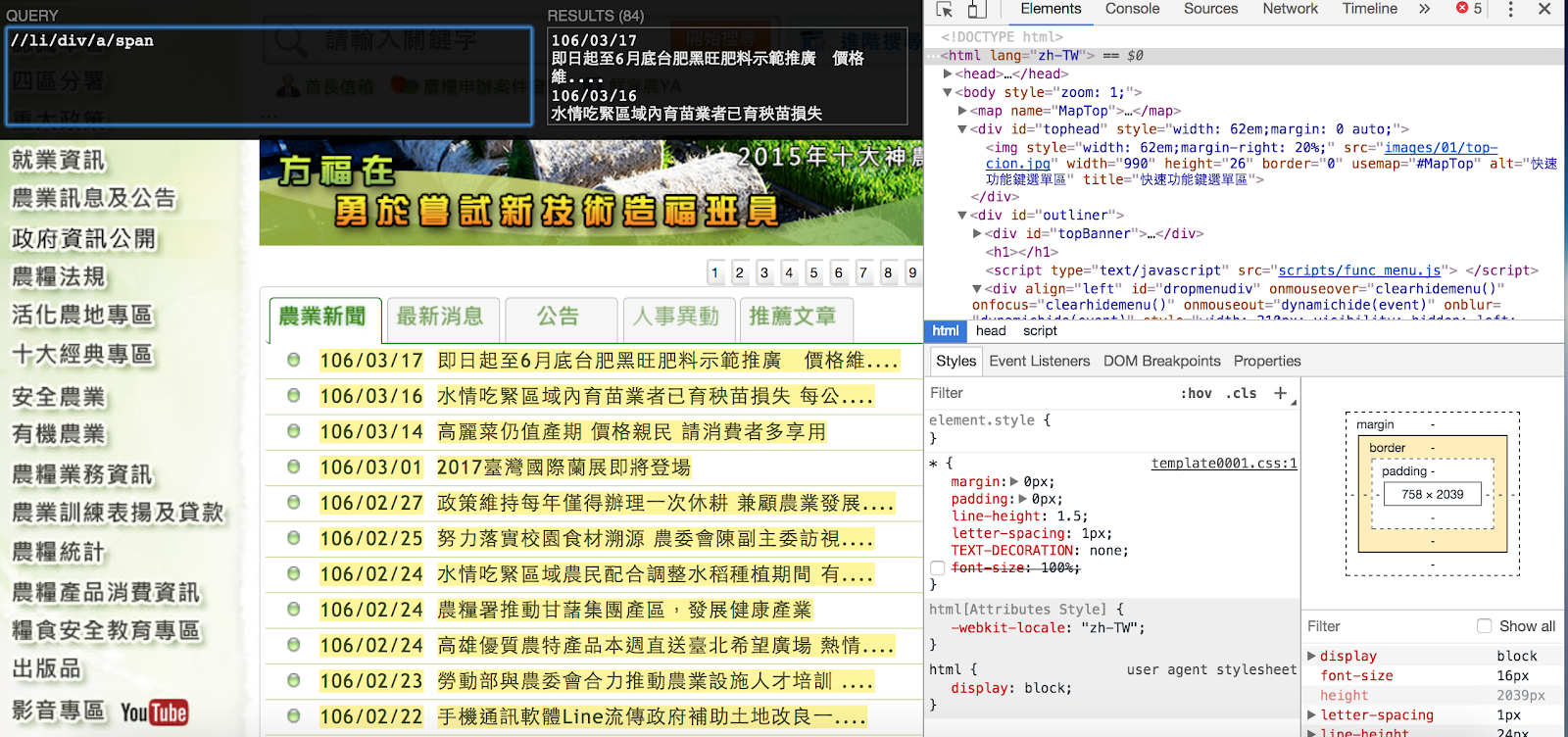
- 測試只抓農業新聞的內容,打//li/div/a/span
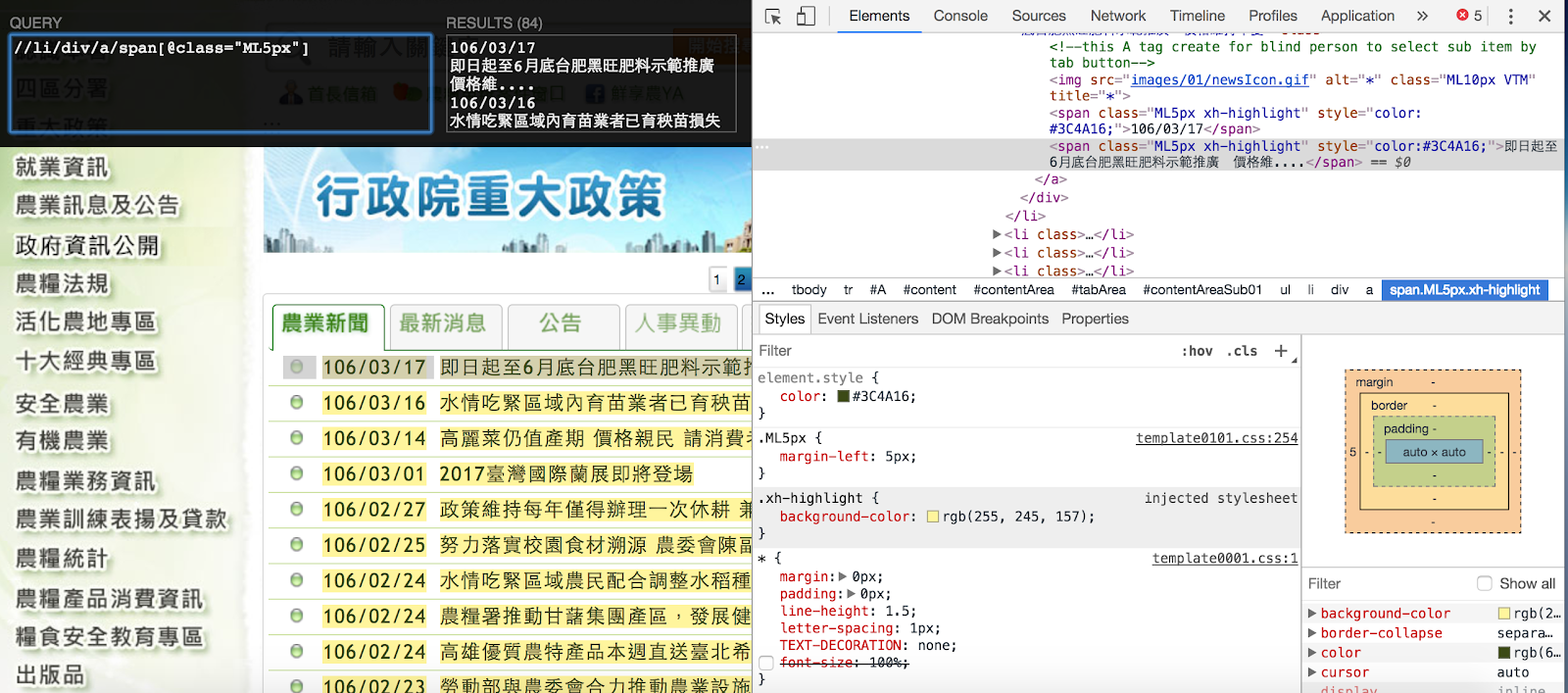
- 使用特定 class 來縮小搜尋範圍
//li/div/a/span[@class="ML5px"]
- 使用特定 id 來只找農業新聞,『*』表示只關心 id 不在乎是哪個標籤夾住的內容
//*[@id=”contentAreaSub01”]/ul/li/div/a/span

#來寫R程式了!
因為引號『“』在 R 程式語言中有別的用意,所以我們要讓電腦知道要使用的是文字版的引號,就要在引號前面加上跳脫字元反斜線『\』
// mac encoding 預設就是utf8
# R 文字處理 - Regular Expression
協助你查詢 R 文字處理結果的網站http://regexr.com
Ex : 不要 \n\t :/[\n\t]/g
Ex : 有大小字母的但自都不要:/([A-Z])\w+/g
這是常用的 regular expression 表有興趣的同學可以參考:https://atedev.wordpress.com/2007/11/23/正規表示式-regular-expression/
Code Example:
rm(list=ls(all.names=TRUE))
library(XML)
library(RCurl)
library(httr)
urlPath <- "https://www.ptt.cc/bbs/movie/index.html"
temp <- getURL(urlPath, encoding = "big5")
xmldoc <- htmlParse(temp)
title <- xpathSApply(xmldoc, "//div[@class=\"title\"]", xmlValue)
title <- gsub("\n", "", title)
title <- gsub("\t", "", title)
author <- xpathSApply(xmldoc, "//div[@class='author']", xmlValue)
path <- xpathSApply(xmldoc, "//div[@class='title']/a//@href")
date <- xpathSApply(xmldoc, "//div[@class='date']", xmlValue)
response<- xpathSApply(xmldoc, "//div[@class='nrec']", xmlValue)
emptyId <- which(title =="(本文已被刪除) [brukling]")
#empty <- author=="-"
#author = author[!empty]
author = author[-emptyId]
date = date[-emptyId]
response = response[-emptyId]
title = title[-emptyId]
alldata <- data.frame(title, author, path, date, response)
write.table(alldata,"pttmovie.csv") #你會在此Script資料夾下得到一個.csv
DEMO : https://pecu.github.io/NTU_R/NTUCSX/parser/parser.html