資料科學與機器學習 k-means、PCA、SVM
Pecu PPT / Code :
參考網站:https://deeplearning4j.org/word2vec
SVR : https://en.wikipedia.org/wiki/Support_vector_machine#Regression
如果你的問題可以用物理性質建構出來的,我們可以使用 simulation
用 PCA 降維,找出最具代表性的最佳投影向量或投影面
SVM 分類 -- R 中的 SVM package 為 e1071
一、安裝以下套件
Step 1. install.packages("devtools")
Step 2. library(devtools)
install_github("ggbiplot", "vqv")
## R 會自動從https://github.com/vqv/ggbiplot下載
## 上面這兩行一定要按順序執行
Step 3. install.packages("scales")
install.packages("e1071")
Step 4. library(scales)
library(grid) ←-grid 是 base package,不需要另外安裝
library(ggbiplot)
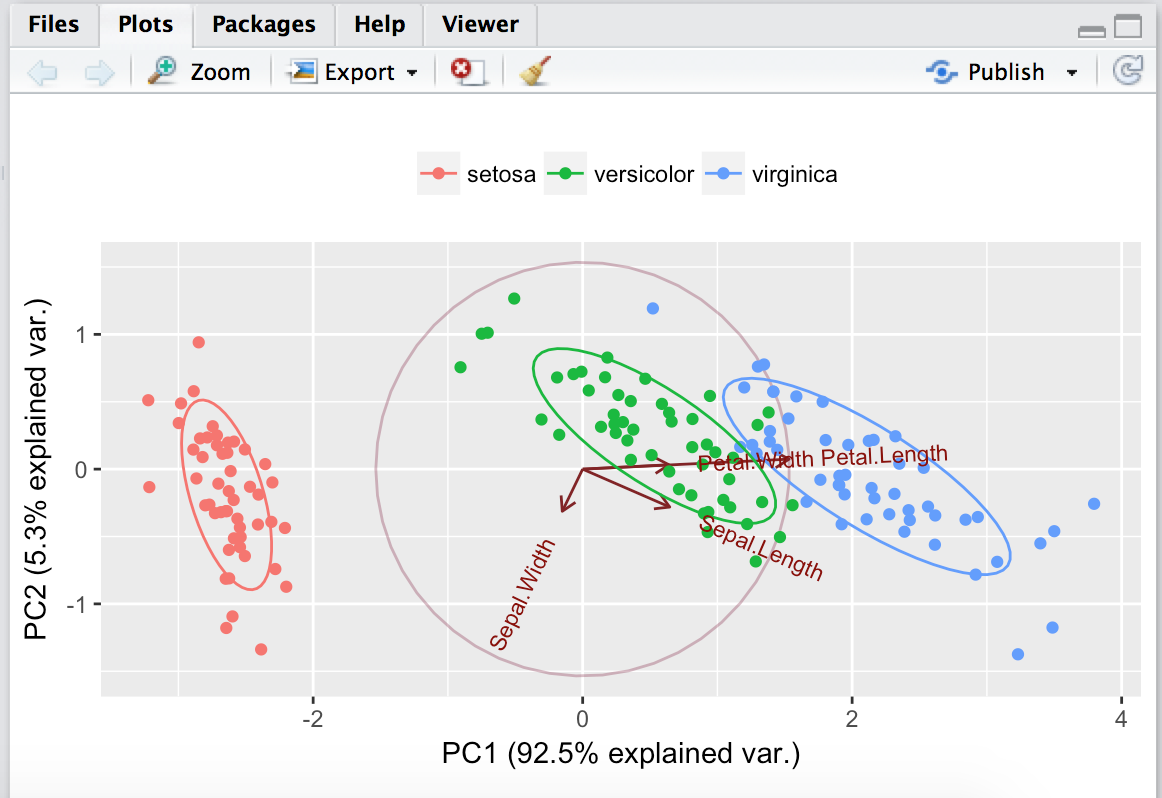
# 範例一:PCA.r
library(devtools)
install_github("ggbiplot", "vqv")
library(scales)
library(grid)
library(ggbiplot)
data(iris)
ir.pca <- prcomp(iris[,1:4])
ir.species <- iris[, 5]
g <- ggbiplot(ir.pca, obs.scale = 1, var.scale = 1,
groups = ir.species, ellipse = TRUE,
circle = TRUE)
g <- g + scale_color_discrete(name = '')
g <- g + theme(legend.direction = 'horizontal',
legend.position = 'top')
print(g)
成果圖:
**# 範例二:MLDM.r
**
如果沒有.txt 檔可以用,請先執行 main.R (會呼叫 pttTestFunction.R)
library(NLP)
library(tm)
library(tmcn)
Sys.setenv(JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_101.jdk/Contents/Home") ###每個人的JAVA_HOME都不一樣唷,請參考20170503筆記
library(rJava)
library(SnowballC)
library(slam)
library(Matrix)
# import data
source("readFromTXT.R")
# corpus to tdm
d.corpus <- Corpus(VectorSource(seg))
tdm <- TermDocumentMatrix(d.corpus,
control = list(wordLengths = c(2, Inf)))
View(inspect(tdm[1:9, 1:10]))
ass = findAssocs(tdm, "", 0.75)
# tf-idf computation
N = tdm$ncol
tf <- apply(tdm, 2, sum)
idfCal <- function(word_doc)
{
log2( N / nnzero(word_doc) )
}
idf <- apply(tdm, 1, idfCal)
doc.tfidf <- as.matrix(tdm)
for(x in 1:nrow(tdm))
{
for(y in 1:ncol(tdm))
{
doc.tfidf[x,y] <- (doc.tfidf[x,y] / tf[y]) * idf[x]
}
}
result = findFreqTerms(tdm, 200)
library(plotly)
topID = lapply(rownames(as.data.frame(ass)), function(x)
which(rownames(tdm) == x))
topID = unlist(topID)
plot_ly(data = as.data.frame(doc.tfidf),
x = as.numeric(colnames(doc.tfidf)),
y = doc.tfidf[topID[10],],
name = rownames(doc.tfidf)[topID[10]],
type = "scatter", mode= "box") %>%
add_trace(y = doc.tfidf[topID[2],],
name = rownames(doc.tfidf)[topID[2]])
# get short doc matrix
nonzero = (doc.tfidf != rep(0,10))
nonzeroid = which(row_sums(nonzero) != 0)
q <- rownames(doc.tfidf[nonzeroid,])
all.term <- rownames(doc.tfidf)
loc <- which(all.term %in% q)
s.tdm <- doc.tfidf[loc,]
View(s.tdm)
# result : cos similarity ranking
cos.sim <- function(x, y)
{
(as.vector(x) %*% as.vector(y)) / (norm(as.matrix(x)) * norm(y))
}
doc.cos <- cos.sim(x=as.matrix(s.tdm[,1]),
y=as.matrix(s.tdm[,2]))
doc.cos <- apply(s.tdm[,2:10], 2, cos.sim,
y=as.matrix(s.tdm[,2]))
orderDoc <- doc.cos[order(doc.cos, decreasing = TRUE)]
plot_ly(data = as.data.frame(orderDoc),
x = rownames(as.data.frame(orderDoc)),
y = orderDoc,
name = rownames(doc.tfidf)[topID[10]],
type = "bar", mode= "box")
library(stats)
kmeansOut <- kmeans(doc.tfidf, 5, nstart = 20)
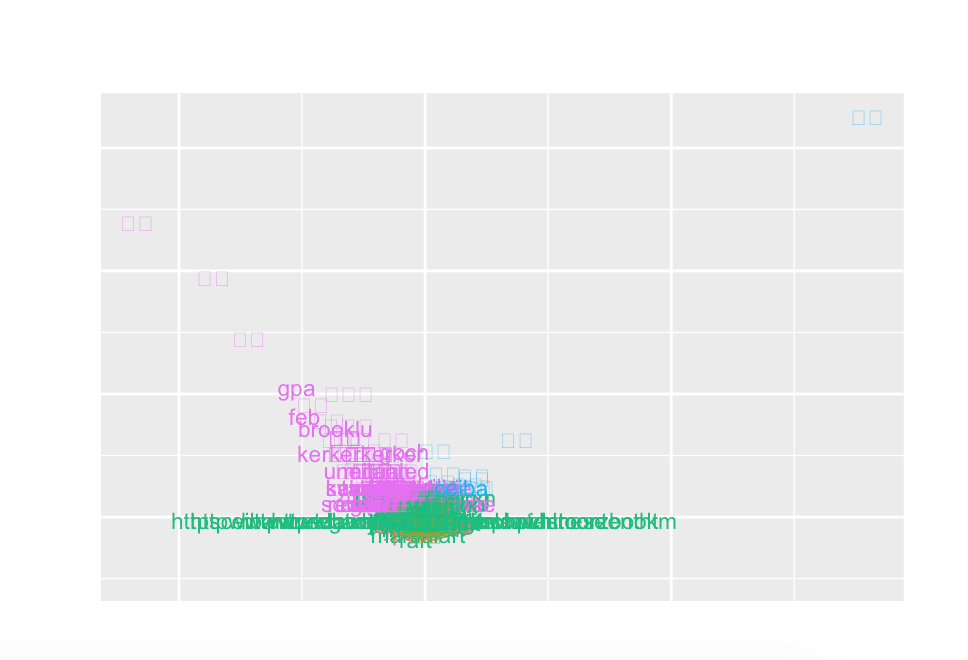
# 範例三:DLTM.r
source('MLDM.R')
testTfidf = doc.tfidf
tfidf.pca <- prcomp(testTfidf)
tfidf.kmeans <- as.factor(kmeansOut$cluster)
g <- ggbiplot(tfidf.pca, obs.scale = 1, var.scale = 1,
groups = tfidf.kmeans, ellipse = TRUE,
circle = TRUE, labels = rownames(testTfidf))
g <- g + scale_color_discrete(name = '')
g <- g + theme(legend.direction = 'horizontal',
legend.position = 'top')
print(g)
結果圖:
# 範例四:SVM.r
set.seed(10111)
x = matrix(rnorm(40), 20, 2)
y = rep(c(-1, 1), c(10, 10))
x[y == 1, ] = x[y == 1, ] + 1
plot(x, col = y + 3, pch = 19)
library(e1071)
dat = data.frame(x, y = as.factor(y))
svmfit = svm(y ~ ., data = dat,
kernel = "linear",
cost = 10, scale = FALSE)
print(svmfit)
plot(svmfit, dat)
make.grid = function(x, n = 75) {
grange = apply(x, 2, range)
x1 = seq(from = grange[1, 1], to = grange[2, 1], length = n)
x2 = seq(from = grange[1, 2], to = grange[2, 2], length = n)
expand.grid(X1 = x1, X2 = x2)
}
xgrid = make.grid(x)
ygrid = predict(svmfit, xgrid)
plot(xgrid, col = c("red", "blue")[as.numeric(ygrid)], pch = 20, cex = 0.2)
points(x, col = y + 3, pch = 19)
points(x[svmfit$index, ], pch = 5, cex = 2)
beta = drop(t(svmfit$coefs) %*% x[svmfit$index, ])
beta0 = svmfit$rho
plot(xgrid, col = c("red", "blue")[as.numeric(ygrid)], pch = 20, cex = 0.2)
points(x, col = y + 3, pch = 19)
points(x[svmfit$index, ], pch = 5, cex = 2)
abline(beta0/beta[2], -beta[1]/beta[2])
abline((beta0 - 1)/beta[2], -beta[1]/beta[2], lty = 2)
abline((beta0 + 1)/beta[2], -beta[1]/beta[2], lty = 2)
load(url("https://statistics.stanford.edu/~tibs/ElemStatLearn/datasets/ESL.mixture.rda")\)
names(ESL.mixture)
rm(x, y)
attach(ESL.mixture)
plot(x, col = y + 1)
dat = data.frame(y = factor(y), x)
fit = svm(factor(y) ~ ., data = dat, scale = FALSE, kernel = "radial", cost = 5)
xgrid = expand.grid(X1 = px1, X2 = px2)
ygrid = predict(fit, xgrid)
plot(xgrid, col = as.numeric(ygrid), pch = 20, cex = 0.2)
points(x, col = y + 1, pch = 19)
func = predict(fit, xgrid, decision.values = TRUE)
func = attributes(func)$decision
xgrid = expand.grid(X1 = px1, X2 = px2)
ygrid = predict(fit, xgrid)
plot(xgrid, col = as.numeric(ygrid), pch = 20, cex = 0.2)
points(x, col = y + 1, pch = 19)
contour(px1, px2, matrix(func, 69, 99), level = 0, add = TRUE)
contour(px1, px2, matrix(prob, 69, 99), level = 0.5, add = TRUE, col = "blue",
lwd = 2)
結果圖:
